
目次
環境
VSCODEのJupyterLab環境を利用します。主要なツールとライブラリのバージョンは以下のようになります。
Python 3.13
pandas 2.2.3
matplotlib 3.9.2
用語
- columns
列のこと、Excelの一番上の行にあるA,B,C,...みたいなもの
属性や特性等の名前でラベルが付けられることが多いと思います。ここでは、列や列名とかで表記することが多いと思います。
- index
行のこと、Excelの一番左の列にある1,2,3,...みたいなもの
連番や名前、何かの値、時系列の値等のラベルが付けられることが多いと思います。ここでは、そのままindexや行名と表記することが多いと思います。
- DataFrame (Pandas.DataFrame)
データの表みたいに扱えるもの(Excelみたいな表計算ソフトでの表みたいなもの)になります。
コンストラクタの引数やオブジェクトのプロパティのcolumnsで列名の設定が可能です。同じようにindexで行名の設定が可能であり、特に設定しなければ0からの連番になります。
|
1 2 3 4 5 6 7 8 |
import pandas as pd data = [ [1,2], [3,4] ] columns=["A","B"] df = pd.DataFrame(data,columns=columns) |
print(df)の結果
|
1 2 3 |
A B 0 1 2 1 3 4 |
- 補足:Series (Pandas.Series)
1次元のデータ、データ列として単純なものを扱えます。indexの設定が可能です。
|
1 2 3 4 |
import pandas as pd data = [1,2,3,4] s = pd.Series(data) |
print(s)の結果
|
1 2 3 4 5 |
0 1 1 2 2 3 3 4 dtype: int64 |
indexを設定すると以下のようになります。
|
1 2 3 4 |
import pandas as pd index=["0:00","6:00","12:00","18:00"] s2 = pd.Series(data,index=index) |
print(s2)の結果
|
1 2 3 4 5 |
0:00 1 6:00 2 12:00 3 18:00 4 dtype: int64 |
生成(データフレーム)
ファイルからの読み込み
Pandasのread_*系のメソッドを利用します。
|
1 2 3 |
import pandas as pd df = pd.read_csv('access_log/20241008.csv') |
read_csvメソッドのcsvの読み込みにかかわるコメントの扱いに疑問がある場合はPandasのドキュメントを確認したほうが良いかもしれません。
他の例として、最初の2行は飛ばしたい情報、区切り文字がタブ、エンコーディングがUTF-16になっているファイルの読み込みは以下のようになります。
|
1 |
df = pd.read_csv("filename.csv", skiprows=2, delimiter="\t", encoding="utf_16") |
べた書き
簡単なテスト用のデータフレームの作成に便利です。ライブラリのimportは省略します。
コンストラクタで設定
データをコンストラクタに直接記述するのもいいですが、分かりづらく感じるのでここでは分けて記述します。
列名とその列のデータ列で設定
|
1 2 3 4 5 |
data = { "A" : [1,2,3], "B" : [4,5,6] } df = pd.DataFrame(data) |
print(df)の結果
|
1 2 3 4 |
A B 0 1 4 1 2 5 2 3 6 |
行データごとに記述を行いたい場合はリストの中に行データを入れたリストを作り、さらにcolumnsを設定するといいかもしれません。
この例ではコンストラクタの引数のキーワードと変数名を合わせています。
|
1 2 3 4 5 6 |
data = [ [1,2,3], [4,5,6] ] columns= ["A","B","C"] df = pd.DataFrame(data=data,columns=columns) |
print(df)の結果
|
1 2 3 |
A B C 0 1 2 3 1 4 5 6 |
空のデータフレームを作成してから設定
ここでやっていることは列の追加で後述でもしていますが、簡単に記述できるのでここでも紹介します。この方法はオブジェクトが変更されるのでこれは破壊的な設定になります。
DataFrameの大きさは最初に代入したデータの数になります。2つ目以降の代入は多すぎても少なすぎてもエラーになります。
データ数が異なる場合は、欠損値の代入を検討しても良いでしょう。pd.NAは実験的機能らしいですので、機能が変更される可能性があります。
|
1 2 |
df = pd.DataFrame() df["A"] = [1,2,3] |
破壊的な設定に対して、非破壊的に設定したい場合はassignを利用します。
|
1 |
df2 = df.assign(B=[4,5,6]) |
print(df)とprint(df2)の結果
|
1 2 3 4 5 6 7 8 |
A 0 1 1 2 2 3 A B 0 1 4 1 2 5 2 3 6 |
欠損値の記述方法
補足として、欠損値の記述方法について考えます。欠損値の記述方法は大まかに以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import math import numpy as np import pandas as pd df = pd.DataFrame() data = [ float('nan'), math.nan, np.nan, pd.NA ] df["欠損値"] = data |
print(df)の結果
|
1 2 3 4 5 |
欠損値 0 NaN 1 NaN 2 NaN 3 <NA> |
データの指定
列の指定
DataFrameオブジェクトに対してハッシュ(辞書)のように指定指定します。
|
1 |
A_data = df["A"] |
複数の列を指定したい場合は、キーをリストにして指定します。
|
1 2 |
columnslist = ["A","B"] AB_data = df[columnslist] # もしくは直接 AB_data = df[["A","B"]] |
一つの値で列を指定した場合に返されるオブジェクトはpandas.Seriesのクラス(これは厳密な言い方ではないと思います)になります。
print(type(A_data))の結果
|
1 |
<class 'pandas.core.series.Series'> |
リストで列を指定した場合に返されるオブジェクトはpandas.DataFrameのクラスになります。
print(type(AB_data))の結果
|
1 |
<class 'pandas.core.frame.DataFrame'> |
数字の番号で列を指定した場合は、上記のより癖のある書き方になりますがilocプロパティを利用します。
A, B, Cの列が順番にある場合にBの列を単純な数値で指定したい場合は以下のようになります。これはpandas.Seriesを返します。
列を数字で指定したい場合は0,1,2,...で指定できます(厳密には配列のアクセス方法のルールだと思います)。
|
1 |
B_data = df.iloc[:,1] |
リストになるとpandas.DataFrameを返します。
|
1 |
B_data = df.iloc[:,[1]] |
スライスも利用できます。スライスは開始値は含まれ、終了値は含まれません。":"のみは配列内の全要素になります。
オブジェクトはpandas.DataFrameを返します。補足としてilocの最初の":"のみは行を指定しています。
|
1 |
AB_data = df.iloc[:,0:2] |
他にも、転置→行の指定→転置で列を指定する方法がありますが、上記の方法で十分だと思うので省略します。
行の指定
locプロパティを用いてハッシュのように指定できます。locはlocationの略で、ilocはinteger locationの略みたいな感じはしますが、ちゃんとしたソースが見つからなかったので分かりませんけれど、覚え方としては十分かもしれません。
locプロパティは行にラベルが付けられているとき、そのラベルを指定できます。数字で指定される場合はその数字はラベルとして認識されてそのラベルの行を指定したことになります。
|
1 2 |
df.index = ["Tokyo","Osaka","Kyoto"] tokyo = df.loc["Tokyo"] |
print(df)の結果並びにprint(tokyo)の結果及び型情報(結果の間に仕切り線を挿入)
|
1 2 3 4 5 6 7 8 9 10 |
A B C Tokyo 1 4 Alice Osaka 2 5 Bob Kyoto 3 6 Charlie --- A 1 B 4 C Alice Name: Tokyo, dtype: object <class 'pandas.core.series.Series'> |
列と同じように返されるオブジェクトはpandas.Seriesになります。ただし、同一値のindexがある場合はpandas.DataFrameが返されます。
これもまた同じように、リストで行を指定するとpandas.DataFrameが返されます。
|
1 |
tokyo = df.loc[["Tokyo"]] |
少し特殊な用途かもしれませんが、文字列の値を持つindexでスライス指定もできます。
この場合はPythonのスライスの機能と違い、終了値が含まれます。
|
1 2 3 4 5 |
print(df.loc["Osaka":]) print(df.loc[:"Osaka"]) print("---") print(df.iloc[1:]) print(df.iloc[:1]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
A B C Osaka 2 5 Bob Kyoto 3 6 Charlie A B C Tokyo 1 4 Alice Osaka 2 5 Bob --- A B C Osaka 2 5 Bob Kyoto 3 6 Charlie A B C Tokyo 1 4 Alice |
数字の番号で行を指定したい場合はilocプロパティを利用します。数字は列の指定と同じように0,1,2,...の数字の指定になります。
返されるオブジェクトはpandas.Seriesになります。
|
1 |
second = df.iloc[1] |
また、列の指定と同じようにリストやスライスで指定でき、返されるオブジェクトはpandas.DataFrameになります。
|
1 2 |
second = df.iloc[[1]] first = df.iloc[0:1] |
locやilocを使わずにdfオブジェクトの指定でスライスを用いた指定を行うと行指定になります。
ただ、個人的な感想ですが、dfオブジェクトを見て、そのアクセス方法で列指定か行指定かを判断するのは少し面倒な感じがするので、
dfオブジェクトに対しては列の指定のみを用いるようにした方がいいかもしれません。
|
1 2 |
first = df[0:1] second = df["Osaka":"Osaka"] |
要素の指定
要素の指定はatプロパティを利用します。指定の仕方は[行名, 列名]になります。
|
1 |
elem = df.at["Tokyo", "A"] |
pandas.Seriesにもatプロパティがあり、その場合は指定する値は一つになります。
|
1 2 |
A_data = df["A"] elem = A_data.at["Tokyo"] |
ラベルではなく、数字の番号で指定する場合はiatプロパティを利用します。指定の方法は[行の番号, 列の番号]になります。開始値は0からになります。
|
1 |
elem = df.iat[0, 0] |
条件の絞り込み
pandas.Seriesクラスに対して、比較演算子などを用いるとbool値のデータを持つpandas.Seriesクラスが返されます。
|
1 2 |
df["A"] = [1,2,3] conditions = df["A"] > 2 |
print(conditions)の結果
|
1 2 3 4 |
0 False 1 False 2 True Name: A, dtype: bool |
このデータをdfオブジェクトに入れると条件でTrueになっている行だけを絞り込むことができます。
|
1 |
filterdf = df[conditions] |
print(df)とprint(filterdf)の結果
|
1 2 3 4 5 6 7 |
A B C 0 1 4 Alice 1 2 5 Bob 2 3 6 Charlie --- A B C 2 3 6 Charlie |
既存のデータフレームからの修正
1列のデータの変更
日付データをPandas.Dateクラスに変更するときに便利。PandasのDatetimeクラスに変換するにはpandas.to_datetimeメソッドを利用。
データを変換するための都合の良い表現にするため、正規表現のライブラリをインポートしています。
正規表現でデータを加工した後にto_datetimeメソッドで変換しています。
|
1 2 3 4 5 6 7 |
import re df["Date"] = [20241001,20241002,20241003] datedata = df["Date"] transform = lambda x : re.sub(r'(\d{4})(\d{2})(\d{2})',r'\1/\2/\3', str(x)) processingdatedata = datedata.apply(transform) df["Date"] = pd.to_datetime(processingdatedata) |
それぞれの変換過程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- step 1: datedata -- 0 20241001 1 20241002 2 20241003 Name: Date, dtype: int64 -- step 2: processingdatedata -- 0 2024/10/01 1 2024/10/02 2 2024/10/03 Name: Date, dtype: object -- step 3: df["Date"] -- 0 2024-10-01 1 2024-10-02 2 2024-10-03 Name: Date, dtype: datetime64[ns] |
追記:上の例は正規表現を使わなくても、データの型を単純にint型からstring型に変換するだけでdatatime型に変換できます。
|
1 |
df["Date"] = pd.to_datetime(datedata.apply(lambda x: str(x))) |
1行のデータの変更
pandas.Seriesを作成して代入をする方法になります。以下の例では、特にindexを設定していない想定でlocプロパティを利用します。ラベルが未設定の場合は、連番が振られています。
まず、DataFrameの列名のリストを取得します。
列数にあったデータがあるpandas.Seriesを作成します。そのとき、pandas.Seriesのindexに取得した列名のリストを設定します。そして、指定した行にデータを代入します。
|
1 2 3 |
columns = df.columns.values changedata = pd.Series([5, 10, 'David'], index=columns) df.loc[0] = changedata |
データの変換前と変換後
|
1 2 3 4 5 6 7 8 9 |
A B C 0 1 4 Alice 1 2 5 Bob 2 3 6 Charlie -- A B C 0 5 10 David 1 2 5 Bob 2 3 6 Charlie |
変更したい行のデータの列数さえ合っていれば、単純なリストでも代入できます。
|
1 2 |
changedata = [5, 10, 'David'] df.loc[0] = changedata |
行の追加
行のデータの変更みたいにdf.locで存在しないindexを指定することで行の追加ができます。
|
1 |
df.loc[3] = [5, 10, 'David'] |
または、Pandas.concatメソッドを利用します。indexの値がデフォルトのままだと、複数の行で同じindex値が出てくるので、ignore_indexをTrueにすることでindexを振り直すことができます。
|
1 2 |
dflist = [df1, df2] concatdf = pd.concat(dflist, ignore_index=True) |
列の追加
列のデータの変更みたいにdfで存在しない列名を指定することで列の追加ができます。
|
1 |
df["D"] = ["data1", "data2", "data3"] |
または、Pandas.concatメソッドを利用して、列を追加することも出来ます。列を結合させたい場合は、axis=1をpandas.concatメソッドの引数に追加します。
|
1 |
concatdf = pd.concat(dflist, axis=1) |
行の削除と列の削除
行の削除と列の削除はdropメソッドを利用します。破壊的な操作ではありません。
行の削除はdropメソッドのindexに削除したい行を指定します。
|
1 2 3 |
df.index = ["Tokyo","Osaka","Kyoto"] dropRow_df = df.drop(index=["Osaka"]) |
列の削除はdropメソッドのcolumnsに削除したい列を指定します。
|
1 2 3 4 5 |
df["A"] = [1,2,3] df["B"] = [4,5,6] df["C"] = ["Alice","Bob","Charlie"] dropColumn_df = df.drop(columns=["B"]) |
破壊的な操作を行いたい場合は、inplaceをTrueにします。
|
1 |
df.drop(columns=["B"], inplace=True) |
left joinの結合
データベースのleft joinみたいにデータフレーム間での結合方法になります。
pandas.mergeメソッドを利用します。
左のデータフレームの列を基準に右のデータフレームを結合します。列を結合させる場合、indexの値は
|
1 |
mergedf = pd.merge(df1, df2) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- df1 -- A B C 0 1 4 Alice 1 2 5 Bob 2 3 6 Charlie -- df2 -- C D one Charlie 3.14 two Bob 3.141 three Alice 3.1415 -- mergedf -- A B C D 0 1 4 Alice 3.1415 1 2 5 Bob 3.141 2 3 6 Charlie 3.14 |
列名の変更
データフレームのcolumnsプロパティで列情報を保存しているpandas.Indexクラスのデータを取得できます。
このオブジェクトを変更することで列名を変更できます。
|
1 2 |
columnslist = df.columns.values columnslist[1] = "E" # 直接 df.columns.values[1] ="E" でも可 |
一応、pandas.Indexクラスのdtypeにあるデータの型を守る必要あります。
print(df.columns)
|
1 |
Index(['A', 'E', 'C'], dtype='object') |
indexの変更
indexを特に設定していない場合はpandas.RangeIndexクラスになっています。このindexはdtypeがnp.int64型なのでindexの一部を文字列に変換することはできません。
print(df.index)の結果
|
1 |
RangeIndex(start=0, stop=3, step=1) |
この状態で、一部のindexの値を文字列にしたいのかという問題はありますが、pandas.Indexを直接生成し直して再設定する方針で一部を文字列にすることはできます。
このとき、最初にindexのリストを取得するときにリテラルのリストとしてコピーすることで、リスト内のデータ型を気にする必要がなくなります。
|
1 2 3 |
indexlist = df.index.values.tolist() indexlist[1] = "one" df.index = pd.Index(indexlist) |
再設定後の結果
|
1 2 3 4 |
A B C 0 1 4 Alice one 2 5 Bob 2 3 6 Charlie |
再設定し直した後だとリストのデータ型がobjectになります。
print(df.index)の結果
|
1 |
Index([0, 'one', 2], dtype='object') |
この状態のindexだと、上の列名を変更したときのように直接indexを変更できるようになります。
|
1 |
df.index.values[2] = "two" |
転置
行列の要素を(i, j)と(j, i)で入れ替えることを転置といいます。
データフレームの列名とindexも入れ替わります。
|
1 |
t = df.T |
print(df)とprint(t)の結果
|
1 2 3 4 5 6 7 8 9 |
A B C 0 1 4 Alice 1 2 5 Bob 2 3 6 Charlie -- 0 1 2 A 1 2 3 B 4 5 6 C Alice Bob Charlie |
分析
記述統計
describeメソッドで記述統計の情報を表示します。
|
1 |
df.describe() |
|
1 2 3 4 5 6 7 8 9 |
A B count 3.0 3.0 mean 2.0 5.0 std 1.0 1.0 min 1.0 4.0 25% 1.5 4.5 50% 2.0 5.0 75% 2.5 5.5 max 3.0 6.0 |
pivotテーブル
データフレームからpivotテーブルを作成します。Pandas.pivot_tableメソッドを利用します。
aggfuncは集約関数の名前を入れます(例えば、df.sumならsumでdf.meanならmeanという関数名)。また、デフォルトの集約関数はmeanになります。
|
1 |
pivottable = pd.pivot_table(df, values=['売上'], index=['店舗'], aggfunc={'売上': 'sum'}) |
print(df)とprint(pivottable)の結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
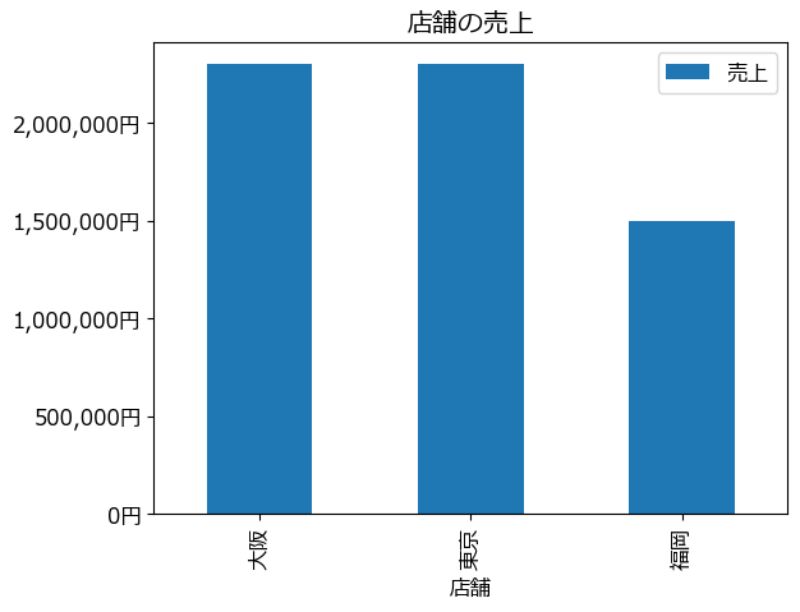
店舗 売上 月 0 東京 1000000 1月 1 大阪 1200000 1月 2 福岡 800000 1月 3 東京 1300000 2月 4 大阪 1100000 2月 5 福岡 700000 2月 -- 売上 店舗 大阪 2300000 東京 2300000 福岡 1500000 |
plot
DataFrameからデータをグラフにプロットできます。特に指定がなければバックグラウンドでmatplotlibライブラリを利用してグラフが作成されます。
細かい制御はmatplotlibのライブラリから設定することになるので結局、matplotlibをインポートしなければならないかもしれません。
例では、データに大きい数値を入れていると、グラフの数値が指数表記になるので、軸の数字をフォーマットし直しています。
pivottableのデータフレームの詳細は省略していますが、上のpivotテーブルの項のデータがそのまま入っています。
日本語の文字を入れている場合はフォントを日本語のあるフォントに設定し直さなければ、Warningが出ます。利用できるフォントの確認や変更についてはplotの補足で後述します。
|
1 2 3 4 5 6 7 8 9 |
import matplotlib.pyplot as plt import matplotlib as mpl plt.rcParams["font.family"] = "Meiryo" plt.rcParams["font.size"] = 12 ax = pivottable.plot(kind='bar', title="店舗の売上") ax.yaxis.set_major_formatter(mpl.ticker.StrMethodFormatter('{x:,.0f}円')) plt.show() |
plotしたグラフの図
plotの補足
Pandasは特に指定がなければmatplotlibライブラリを利用してグラフを生成します。なので、グラフの設定に問題がある場合はmatplotlibライブラリを読み込んで設定を変更する必要があります。
例えば、利用できるフォントを確認したい場合はmaplotlib.font.manager.get_font_names()で使えるフォントを確認します。
|
1 2 3 |
import matplotlib.font_manager matplotlib.font_manager.get_font_names() |
そして、フォントを変更したい場合は
|
1 2 3 4 |
import matplotlib.pyplot as plt plt.rcParams["font.family"] = "Meiryo" plt.rcParams["font.size"] = 12 |
のように確認したフォントを指定すると変更できます。