
この記事ではPythonでExcelファイルを操作できるopenpyxlを簡単に紹介します。
Excelの作業を自動化するツールとしてExcel VBAがよく候補になります。
Pythonでもopenpyxlというライブラリを用いれば、Excelの作業を自動化することができます。PythonでExcelの作業を自動化するメリットとして、Pythonのデータ処理に長けた強力なライブラリ等の多くのライブラリを利用できる点やPythonの強力な表記方法を利用できる点があります。また、Pythonのプログラミング言語として学びやすく、実用面としても用途によっては十分にVBAの代わりができます。
この記事で、利用しているOS・Python・openpyxlのバージョンは以下の通りになります。
- Windows 10
- Python 3.8.5
- openpyxl 3.0.5
目次
openpyxlのインストール
pip installでopenpyxlを指定することで簡単にインストールできます。
|
1 |
pip install openpyxl |
Excelファイルの作成
ワークブックの作成はopenpyxlからWorkbookをインポートし、Workbook()でWorkbookオブジェクトを作成できます。
Workbookオブジェクトからcreate_sheet()を用いることでワークシートの作成できます。
また、Workbookオブジェクトのcopy_worksheet()を用いることでワークシートをコピーできます。
Worksheetオブジェクトのtitleプロパティを変更することでシート名を変更できます。
Workbookオブジェクトのsave()を用いることで、Excelファイルの保存ができます。
以下のコードはopenpyxlのチュートリアルとほぼ同じになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from openpyxl import Workbook wb = Workbook() ws = wb.active ws1 = wb.create_sheet("Mysheet_append") # シートの最後に挿入 ws2 = wb.create_sheet("Mysheet_first", 0) # シートの1番目に挿入 ws3 = wb.create_sheet("Mysheet_penultimate", -1) # シートの最後から2番目に挿入 ws4 = wb.copy_worksheet(ws) # シートのコピー ws.title = "Change_Title" print(wb.sheetnames) wb.save('excel_create.xlsx') |
実行すると以下のようにワークシートが作成されます。

また、print文では以下のように、ワークシートの名前が出力されます。
|
1 |
['Mysheet_first', 'Change_Title', 'Mysheet_penultimate', 'Mysheet_append', 'Sheet Copy'] |
データの挿入
ワークシートのセルへのデータ挿入はいくつか方法があります。
例えば、Worksheetオブジェクトの変数wsに対して、
* ws["A1"]のようなExcelのように指定して代入する方法
* ws.cell(行の位置,列の位置,値)で値をセットする方法
があります。
|
1 2 3 4 5 6 7 8 9 10 11 |
from openpyxl import Workbook wb = Workbook() ws = wb.active ws["A1"]="Data Insert" for row in range(2,21): for col in range(1,6): ws.cell(row,col,"Row"+str(row)+"-"+"Col"+str(col)) wb.save('excelfile_insertdata.xlsx') |
データが挿入されたExcelファイルは以下のようになります。
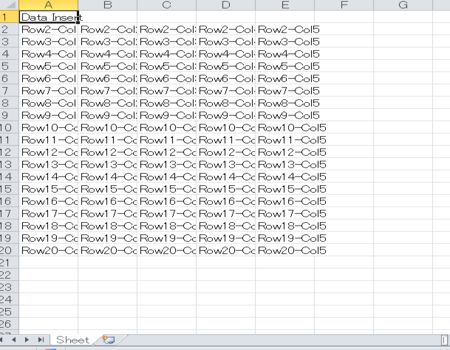
データのロード
既存のExcelファイルをロードするにはload_workbookをインポートしてから、Excelファイルのファイルパスを指定します。
|
1 2 3 4 5 6 7 8 |
from openpyxl import Workbook,load_workbook wb = load_workbook('excelfile_load.xlsx') ws = wb["Sheet1"] print(ws["A1"].value) for row in range(2,4): for col in range(1,3): print(ws.cell(row=row, column=col).value) |
ロードされるExcelファイルは以下のようなものを利用します。
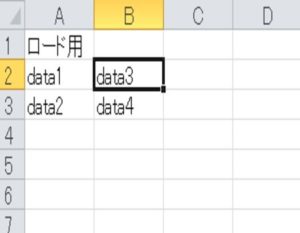
Excelファイルがロードされると、print文で以下のように出力されます。
|
1 2 3 4 5 |
ロード用 data1 data3 data2 data4 |
画像の挿入
画像の挿入をしたい場合は、openpyxl.drawing.imageからImageをインポートします。
Image()で挿入したい画像のファイルパスを指定します。画像の大きさはheightやwidthのプロパティで変更できます(px単位)。
その後に、Worksheetオブジェクトからadd_image()で画像を挿入できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from openpyxl import Workbook from openpyxl.drawing.image import Image wb = Workbook() ws = wb.active ws.title = "image_set" img = Image("PC_image.jpg") img.height=200 img.width=250 ws.add_image(img,"B2") wb.save("excelfile_image.xlsx") |
実行すると以下のような画像が挿入されたExcelファイルを作成できます。
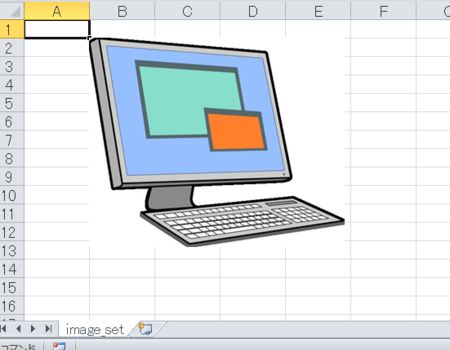
グラフの挿入
グラフを挿入したい場合はopenpyxl.chartから利用したいグラフをインポートします。
ここでは棒グラフを使用するため、BarChartをインポートします。
また、範囲を参照するためにReferenceもインポートします。
Reference(range_string=)を利用するとworksheet名から始まるExcelで利用する範囲の文字列で、範囲の参照を行うことができます。
Reference(worksheet=ws,min_col=,max_col,min_row,max_row)を利用するとWorksheetオブジェクトで範囲における列の最小と最大の列番号と行の最小と最大の行番号を指定して、範囲の参照を行うことができます。(表の中で番号はそれぞれ1から始まります。1行目の番号は1、1列目の番号は1)
その後、グラフオブジェクトのadd_data()で値を入れ、Worksheetオブジェクトのadd_chart()で指定した場所にグラフを入れることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from openpyxl import Workbook from openpyxl.chart import BarChart, Reference wb = Workbook() ws = wb.active ws.title = "graph_create" for row in range(1,11): ws.cell(row,1,row*2) #values = Reference(worksheet=ws,min_col=1,max_col=1,min_row=1,max_row=10) values = Reference(range_string="graph_create!A1:A10") chart = BarChart() chart.add_data(values) ws.add_chart(chart,"C2") wb.save("excelfile_graph.xlsx") |
グラフが挿入されたExcelファイルは以下のようになります。
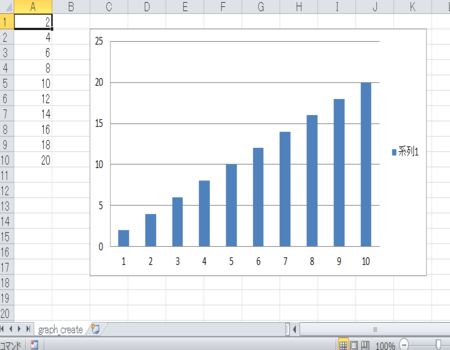
openpyxlでPandasを利用
Pythonには、データ処理のライブラリとして、Pandasがあります。openpyxlではPandasのデータフレームを利用することができます。
pandasのインストールは以下のコマンドでできます。
|
1 |
pip install pandas |
Pandasを利用するためにpandasをインポートします。
pandasのデータフレームをExcelの行に変換するために、openpyxl.utils.dataframeからdataframe_to_rowsをインポートします。
ここでは、dataframe_to_rows()でヘッダー行の後に空行が出てくるのが気になったため、if(row != [None])で空行を抜く処理を入れています。
さらにopenpyxlでセルのスタイルで"Pandas"というスタイルがあるため、ヘッダー行とインデックス列を"Pandas"というスタイルに変更しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
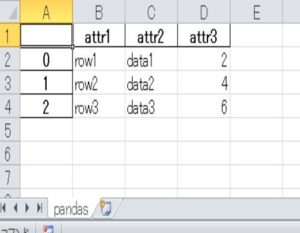
import pandas as pd from openpyxl import Workbook from openpyxl.utils.dataframe import dataframe_to_rows df = pd.DataFrame({ "attr1":["row1","row2","row3"], "attr2":["data1","data2","data3"], "attr3":[2,4,6] }) wb = Workbook() ws = wb.active ws.title = "pandas" for row in dataframe_to_rows(df): if(row != [None]): ws.append(row) for cell in ws["A"] + ws["1"]: cell.style = "Pandas" wb.save("excelfile_pandas.xlsx") |
実行してExcelファイルを作成すると以下のようになります。
openpyxlで簡単なアンケートデータの集計を行なってみる
もう少し実用的な例として、アンケートデータ集計のExcelファイルを作成したいと思います。
入力データとして、以下のような性別と年齢と都道府県があるcsvファイルを用意して、
|
1 2 3 4 5 |
女,37,三重県 男,21,佐賀県 男,35,兵庫県 女,49,兵庫県 ... |
後から、選択肢が4つある、3つのアンケートにランダムに答えたと仮定したデータをつけ足して、アンケートデータとします。
出力するExcelファイルには、
- アンケートデータのシート
- アンケート1の集計結果のシート
- アンケート2の集計結果のシート
- アンケート3の集計結果のシート
を作成します。
アンケートの集計結果として、
- それぞれの選択肢の回答数
- 年齢別の回答数の数
- 年齢別の選択肢の回答数
- 男女ごとの回答数
- 男女別の選択肢の回答数
- 都道府県別の回答数
- 都道府県別の選択肢の回答数
をそれぞれ表にして、さらにグラフにしたものとします。
まず、上の内容の実装例として、ソースコードの全体を紹介して、そのあとで部分的に解説を行いたいと思います。
コーディングが拙い部分もあると思いますが、ご了承ください。
また、出力結果のグラフも環境によってはグラフ同士が重なったりと、表示がうまくいかない場合もあるかもしれません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 |
import numpy as np import pandas as pd from openpyxl import Workbook from openpyxl.utils.dataframe import dataframe_to_rows from openpyxl.worksheet.worksheet import Worksheet from openpyxl.chart import BarChart, Reference from pandas.core.frame import DataFrame def main(): questionnaire_survey("test_data.csv", "questionnaire_survey.xlsx") def questionnaire_survey(infile:str, outfile:str): df = data_input(infile) wb = Workbook() ws = wb.active ws.title = "アンケートデータ" for row in dataframe_to_rows(df): if(row != [None]): ws.append(row) for cell in ws["A"] + ws["1"]: cell.style = "Pandas" ws_name = ["アンケート1", "アンケート2", "アンケート3"] ws_case = [wb.create_sheet(x) for x in ws_name] for i in range(len(ws_name)): graphsheet_create(ws_name[i], df, ws_case[i]) wb.save(outfile) def data_input(infile:str): df = pd.read_csv(infile,header=None,names=["性別","年齢","都道府県"]) df["アンケート1"] = np.random.randint(1, 5, size=df.shape[0]) df["アンケート2"] = np.random.randint(1, 5, size=df.shape[0]) df["アンケート3"] = np.random.randint(1, 5, size=df.shape[0]) return df def graphsheet_create(colname:str,df:DataFrame, ws:Worksheet): answer_count_graph(colname, df, ws, 1, 1) answer_age_graph("年齢", df, ws, 1, 1+20*1) answer_age_count("年齢",colname, df, ws, 1, 1+20*2) gender_graph("性別", df, ws, 1, 1*20*3) gender_count_graph("性別",colname, df, ws, 1, 1+20*4) prefectures_graph("都道府県", df, ws, 1, 1+20*5) prefectures_count_graph("都道府県",colname, df, ws, 1, 1+20*5+55) def answer_count_graph(colname:str, df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = [1, 2, 3, 4] data_rows_name = [str(x) for x in choices] header = ["選択肢", "人数"] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y # 選択肢1, 2, 3, 4の4行分の名前の範囲 colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) # 選択肢1, 2, 3, 4の4行分のデータの範囲 values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_title=colname+"の回答" chart_x_axis_title="選択肢" chart_y_axis_title="回答数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 col[0]["values"] = [header[0], *data_rows_name] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目 col[1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 calc_values = [(df[colname] == value).sum() for value in choices] col[1]["values"] = [header[1], *calc_values] for key, value in zip(col[1]["keys"], col[1]["values"]): if value not in [header[1]]: max_v = value if max_v < value else max_v sheet[pos_x+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) chart = BarChart() values = Reference(ws, min_col=values_ref_min_col, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.title = chart_title chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y, chart_pos_x).coordinate) def answer_age_graph(colname:str,df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = [20, 30, 40, 50, 60, 70] data_rows_name = ["-19", "20-29", "30-39", "40-49", "50-59", "60-69", "70-"] header = ["年齢", "人数"] footer = ["合計:", len(df[colname])] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_title="年齢別の回答人数" chart_x_axis_title="年齢" chart_y_axis_title="人数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+2)] # header行, footer行 +2 col[0]["values"] = [header[0], *data_rows_name, footer[0]] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目 col[1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+2)] # header行, footer行 +2 calc_first = (df[colname] < choices[0]).sum() calc_middle = [ ((choices[i] <= df[colname]) & (df[colname] < choices[i+1])).sum() for i in range(len(choices)-1) ] calc_last = (choices[-1] < df[colname]).sum() calc_values = [calc_first,*calc_middle,calc_last] col[1]["values"] = [header[1], *calc_values, footer[1]] for key, value in zip(col[1]["keys"], col[1]["values"]): if value not in [header[1], footer[1]]: max_v = value if max_v < value else max_v sheet[pos_x+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) chart = BarChart() values = Reference(ws, min_col=values_ref_min_col, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.title = chart_title chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y, chart_pos_x).coordinate) def answer_age_count(agecolname:str,colname:str,df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = [20, 30, 40, 50, 60, 70] data_rows_name = ["-19", "20-29", "30-39", "40-49", "50-59", "60-69", "70-"] data_cols_value = [1, 2, 3, 4] data_cols_name = [str(x) for x in data_cols_value] header = ["年齢/選択肢", *data_cols_name] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_title=lambda x: "年齢別の選択肢"+ x + "の回答数" chart_x_axis_title="年齢" chart_y_axis_title="回答数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 col[0]["values"] = [header[0], *data_rows_name] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目以降 for col_i in range(len(data_cols_value)): # col_i+1で2列目以降 col[col_i+1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 calc_first = ((df[agecolname] < choices[0]) & (df[colname] == data_cols_value[col_i])).sum() calc_middle = [ ((choices[i] <= df[agecolname]) & (df[agecolname] < choices[i+1]) & (df[colname] == data_cols_value[col_i])).sum() for i in range(len(choices)-1) ] calc_last = ((choices[-1] < df[agecolname]) & (df[colname] == data_cols_value[col_i])).sum() calc_values = [calc_first,*calc_middle,calc_last] col[col_i+1]["values"] = [header[col_i+1], *calc_values] for key, value in zip(col[col_i+1]["keys"], col[col_i+1]["values"]): if value not in [header[col_i+1]]: max_v = value if max_v < value else max_v sheet[pos_x+col_i+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) for col_i in range(len(data_cols_value)): chart = BarChart() values = Reference(ws, min_col=values_ref_min_col+col_i, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.title = chart_title(data_cols_name[col_i]) chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y, chart_pos_x+col_i*10).coordinate) def gender_graph(colname:str,df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = ["男", "女"] data_rows_name = ["男", "女"] header = ["性別", "人数"] footer = ["合計:", len(df[colname])] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_title="男女別の回答人数" chart_x_axis_title="性別" chart_y_axis_title="人数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+2)] # header行, footer行 +2 col[0]["values"] = [header[0], *data_rows_name, footer[0]] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目 col[1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+2)] # header行, footer行 +2 calc_values = [(df[colname] == x).sum() for x in choices] col[1]["values"] = [header[1], *calc_values, footer[1]] for key, value in zip(col[1]["keys"], col[1]["values"]): if value not in [header[1], footer[1]]: max_v = value if max_v < value else max_v sheet[pos_x+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) chart = BarChart() values = Reference(ws, min_col=values_ref_min_col, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.title = chart_title chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y, chart_pos_x).coordinate) def gender_count_graph(gendercolname:str,colname:str,df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = ["男","女"] data_rows_name = ["男", "女"] data_cols_value = [1, 2, 3, 4] data_cols_name = [str(x) for x in data_cols_value] header = ["性別/選択肢", *data_cols_name] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_title=lambda x: "男女別の選択肢"+ x + "の回答数" chart_x_axis_title="性別" chart_y_axis_title="回答数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 col[0]["values"] = [header[0], *data_rows_name] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目以降 for col_i in range(len(data_cols_value)): # col_i+1で2列目以降 col[col_i+1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 calc_values = [((df[colname] == data_cols_value[col_i]) & (df[gendercolname] == x)).sum() for x in choices] col[col_i+1]["values"] = [header[col_i+1], *calc_values] for key, value in zip(col[col_i+1]["keys"], col[col_i+1]["values"]): if value not in [header[col_i+1]]: max_v = value if max_v < value else max_v sheet[pos_x+col_i+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) for col_i in range(len(data_cols_value)): chart = BarChart() values = Reference(ws, min_col=values_ref_min_col+col_i, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.title = chart_title(data_cols_name[col_i]) chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y, chart_pos_x+col_i*10).coordinate) def prefectures_graph(colname:str,df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = get_all_prefectures() data_rows_name = get_all_prefectures() header = ["都道府県", "人数"] footer = ["合計:", len(df[colname])] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_width=25 # グラフの幅(cm) chart_title="都道府県別の回答人数" chart_x_axis_title="都道府県" chart_y_axis_title="人数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+2)] # header行, footer行 +2 col[0]["values"] = [header[0], *data_rows_name, footer[0]] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目 col[1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+2)] # header行, footer行 +2 calc_values = [(df[colname] == x).sum() for x in choices] col[1]["values"] = [header[1], *calc_values, footer[1]] for key, value in zip(col[1]["keys"], col[1]["values"]): if value not in [header[1], footer[1]]: max_v = value if max_v < value else max_v sheet[pos_x+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) chart = BarChart() values = Reference(ws, min_col=values_ref_min_col, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.width=chart_width chart.title = chart_title chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y, chart_pos_x).coordinate) def prefectures_count_graph(prefcolname:str,colname:str,df:DataFrame, ws:Worksheet, offset_x:int, offset_y:int): choices = get_all_prefectures() data_rows_name = get_all_prefectures() data_cols_value = [1, 2, 3, 4] data_cols_name = [str(x) for x in data_cols_value] header = ["都道府県/選択肢", *data_cols_name] table_start_pos_x=1 table_start_pos_y=1 pos_x = table_start_pos_x+offset_x pos_y = table_start_pos_y+offset_y chart_pos_x = pos_x+len(header)+1 chart_pos_y = pos_y colvalues_ref_min_col=pos_x colvalues_ref_min_row=pos_y+1 colvalues_ref_max_row=pos_y+len(data_rows_name) values_ref_min_col=pos_x+1 values_ref_min_row=pos_y+1 values_ref_max_row=pos_y+len(data_rows_name) max_v=0 # グラフデータの最大値 グラフ目盛りのオートスケール計算に使用 chart_y_axis_scaling_min=0 # グラフの目盛りの最小値 chart_width=25 # グラフの幅(cm) chart_title=lambda x: "都道府県別の選択肢"+ x + "の回答数" chart_x_axis_title="都道府県" chart_y_axis_title="回答数" chart_legend=None sheet = {} col = [{} for x in range(len(header))] for i in range(len(header)): sheet[pos_x+i] = {} # 1列目 col[0]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 col[0]["values"] = [header[0], *data_rows_name] for key, value in zip(col[0]["keys"], col[0]["values"]): sheet[pos_x][key] = value # 2列目以降 for col_i in range(len(data_cols_value)): # col_i+1で2列目以降 col[col_i+1]["keys"] = [pos_y+i for i in range(len(data_rows_name)+1)] # header行 +1 calc_values = [((df[colname] == data_cols_value[col_i]) & (df[prefcolname] == x)).sum() for x in choices] col[col_i+1]["values"] = [header[col_i+1], *calc_values] for key, value in zip(col[col_i+1]["keys"], col[col_i+1]["values"]): if value not in [header[col_i+1]]: max_v = value if max_v < value else max_v sheet[pos_x+col_i+1][key] = value # 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) for col_i in range(len(data_cols_value)): chart = BarChart() values = Reference(ws, min_col=values_ref_min_col+col_i, min_row=values_ref_min_row, max_row=values_ref_max_row) chart.add_data(values) colvalues = Reference(ws, min_col=colvalues_ref_min_col, min_row=colvalues_ref_min_row, max_row=colvalues_ref_max_row) chart.set_categories(colvalues) # ※chart.add_data()の後にデータの名前をセットする # オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) chart.y_axis.scaling.min = chart_y_axis_scaling_min chart.width=chart_width chart.title = chart_title(data_cols_name[col_i]) chart.x_axis.title = chart_x_axis_title chart.y_axis.title = chart_y_axis_title chart.legend = chart_legend ws.add_chart(chart, ws.cell(chart_pos_y+(col_i//2)*20, chart_pos_x+(col_i%2)*15).coordinate) def get_all_prefectures(): return [ "北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県", "茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県", "新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県", "岐阜県", "静岡県", "愛知県", "三重県", "滋賀県", "京都府", "大阪府", "兵庫県", "奈良県", "和歌山県", "鳥取県", "島根県", "岡山県", "広島県", "山口県", "徳島県", "香川県", "愛媛県", "高知県", "福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県", ] if __name__ == "__main__": main() |
出力結果として出来上がるExcelファイルは以下のようになります。
アンケートデータ
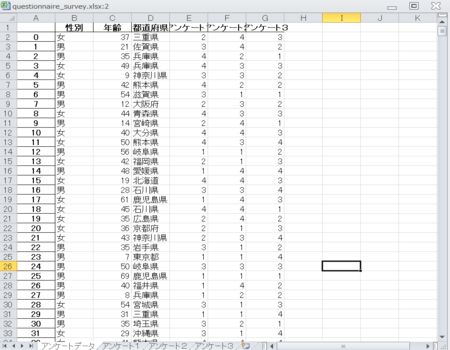
集計結果の図(一部)
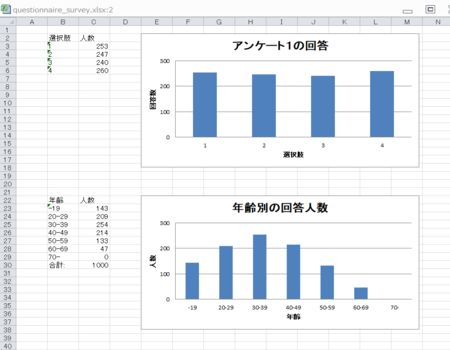
集計結果の図(全体図)
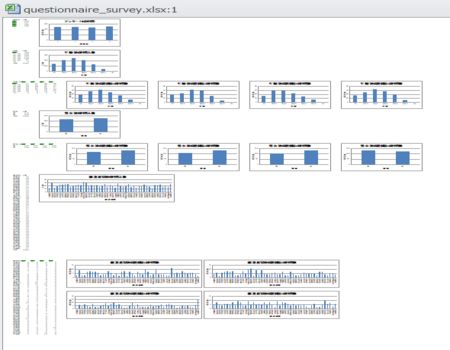
それぞれの機能の集計結果の計算方法
アンケートの集計結果で、内容と上記のソースコードの関数での対応は以下のようになります。
- それぞれの選択肢の回答数 answer_count_graph()
- 年齢別の回答人数 answer_age_graph()
- 年齢別の選択肢の回答数 answer_age_count()
- 男女別の回答人数 gender_graph()
- 男女別の選択肢の回答数 gender_count_graph()
- 都道府県別の回答人数 prefectures_graph()
- 都道府県別の選択肢の回答数 prefectures_count_graph()
それぞれの集計結果の計算方法は主にPandasのDataFrameを用いて計算しています。
データフレームに比較演算子を用いると以下のような結果が得られます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
>>> import pandas as pd >>> import numpy as np >>> >>> df = pd.DataFrame(np.arange(12).reshape(3,4)) >>> print(df) 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 >>> print(1 < df) 0 1 2 3 0 False False True True 1 True True True True 2 True True True True |
これを特定の列で用いると以下のようなDataFrameが得られ、
|
1 2 3 4 5 |
>>> print(1 < df[0]) 0 False 1 True 2 True Name: 0, dtype: bool |
さらに、このboolean列にDataFrame.sum()を用いると
|
1 2 |
>>> print((1 < df[0]).sum()) 2 |
Trueの数を得られます。また、複数の条件で行いたい場合は、条件を'&'(andの意味)や'|'(orの意味)や'~'(notの意味)を用いることができます。
|
1 2 3 4 5 6 |
>>> print((1 < df[0]) & (df[1] == 9)) 0 False 1 False 2 True dtype: bool >>> print(((1 < df[0]) & (df[1] == 9)).sum()) |
基本的にこの方法で集計結果を得られます。
年齢別の回答人数(answer_age_graph)では少し、変わった計算の仕方をしています。
|
1 2 3 4 5 6 |
calc_first = (df[colname] < choices[0]).sum() calc_middle = [ ((choices[i] <= df[colname]) & (df[colname] < choices[i+1])).sum() for i in range(len(choices)-1) ] calc_last = (choices[-1] < df[colname]).sum() calc_values = [calc_first,*calc_middle,calc_last] |
これはまず、年齢の区切りの配列(変数名がおかしい気がしますが気にしないで)を持ち、
|
1 |
choices = [20, 30, 40, 50, 60, 70] |
最初のデータと最後のデータはそれぞれ通常の方法で、集計結果を出し、
|
1 2 |
calc_first = (df[colname] < 20).sum() calc_last = (70 <= df[colname]) |
中間にある方法は、Pythonの内包表記で、さらに2つの要素を取り出して、それぞれの年齢の比較を行っています。
以下は2つの要素を取り出して、どのような値が出力されるかの様子です。
|
1 2 3 |
>>> tmp = [str(choices[i])+','+str(choices[i+1]) for i in range(len(choices)-1)] >>> print(tmp) ['20,30', '30,40', '40,50', '50,60', '60,70'] |
表の記入方法について
表は辞書型のデータ構造を利用して、記入されます。表のデータ構造は
|
1 2 3 4 5 6 7 8 9 |
{ 列番地1: { 行番地 : 値, ... }, 列番地2: ... } |
のように保存されます。
こうすることで、表の記入を行うときにループで記入を行うことができます。
|
1 2 3 4 |
# 表の記入 for col_k,col_v in sheet.items(): for row_k,v in col_v.items(): ws.cell(row_k, col_k, v) |
グラフの目盛りのオートスケール計算
グラフのオートスケールの計算は検索してもなかなか出てこなかったので、自作したものになります。
|
1 2 3 4 5 6 7 |
# オートスケール計算 if str(max_v)[0] in ["1"]: chart.y_axis.majorUnit = 5 * (10 ** (len(str(max_v // 2))-1)) elif str(max_v)[0] in ["2","3"]: chart.y_axis.majorUnit = 1 * (10 ** (len(str(max_v // 2))-1)) else: chart.y_axis.majorUnit = 2 * (10 ** (len(str(max_v // 2))-1)) |
グラフの目盛りの計算は、グラフでの最小値と最大値で求めます。グラフの最小値と最大値はグラフの幅を計算するために用います。
今回の例では、グラフの最小値は0で固定されているので、グラフの最大値を表のデータ構造に保存するときに変数(max_v)に記憶しておきます。
グラフの目盛りには1, 2, 5の倍数の数字を使った目盛りを利用するといいらしいので、目盛りに1, 2, 5の倍数を用いた計算方法を考えます。
ここで、例えば、グラフの目盛りを付ける場合、最低でも(グラフの幅/2)の部分でグラフの目盛りをつけたいです。
グラフの幅10のグラフに対して、(グラフの幅/2)は5となり、5のところにつけられそうです。
グラフの幅9のグラフに対して、(グラフの幅/2)は4(小数切り捨て)となり、1,2,5のどれかを使うとすると2が妥当と考えます。
同様に続けて、3のグラフに対して、(グラフの幅/2)は1(小数切り捨て)となり、1が妥当と考えます。
この結果で、
- 一番上位の桁が1の場合は、5の倍数を
- 一番上位の桁が2,3の場合は、1の倍数を
- それ以外は2の倍数
になります。
グラフの目盛りに使う数字はおおまかに決まったので、次はその数字の桁数について考えます。扱う数字は正の整数で、とりあえず1000という数字について考えてみます。
1000につける目盛りは500にしたいので、5に100倍した数値になるだろうと考えます。
(グラフの幅/2)は500で、3桁あります。10のべき乗を考えて、10の(グラフの幅/2)の桁数-1乗で桁数も良いだろうと考えます。
同様に900や300で考えても、その数値は目盛りとしては使えそうなのでプログラムで記述したものになります。
ただし、桁数の計算はプログラム上ではすべて、(グラフの幅/2)をして桁数を計算していますが、1, 2の倍数の目盛りを計算する場合は、グラフの幅の桁数は(グラフの幅/2)にしても桁が落ちることがないのでわざわざ(グラフの幅/2)を計算する必要はありません。
グラフの設定
今回の例で用いたグラフの設定は以下のような意味になります。
|
1 2 3 4 5 6 7 8 9 |
chart = BarChart() # グラフオブジェクトの作成 chart.y_axis.majorUnit # グラフの目盛り chart.y_axis.scaling.min # グラフの最小値 chart.width # グラフの幅(単位はcm) chart.title # グラフのタイトル chart.x_axis.title # グラフの横軸のタイトル chart.y_axis.title # グラフの縦軸のタイトル chart.legend # 凡例 |
まとめ
アンケートデータの集計プログラムはcsvファイルを入力として、Excelファイルを出力できます。csvファイルから集計結果の表やグラフなども自動で作成できます。
このプログラムの改善点はコマンドライン引数から入力ファイルや出力ファイルを指定できるようにする等、多々ありますが、このようにPythonを使用してopenpyxlでのExcelの作業の自動化は十分効果的だと思います。
Excelの作業の自動化は基本的にVBAが選択肢になりますが、Pythonも検討する価値があると思います。Excelでフォームコントロールを使用したい場合はVBAが選択肢になると思いますが、単純な作業の自動化はVBAよりPythonの方が書きやすく、良いと感じます。